While (personal) computers have become increasingly powerful over the last years there are still lots of workloads that easily bring even the best workstation to its knees. Running huge Monte-Carlo simulations or training thousands of models takes hours, if not days even on very beefy machines. Now enter Azure Batch processing. Azure Batch is a Microsoft cloud computing service that allows you to run your computations on multiple machines in the cloud and collect the results back in R once the computations are done using doAzureParallel a foreach backend.
This article is intended as a quick start guide on how to use Azure Batch from R to distribute computations to the cloud and is based on Microsoft’s online documentation.
Prerequisites
To start, you first need to install the following packages and load doAzureParallel:
# Install the devtools package
install.packages("devtools")
# Install rAzureBatch package
devtools::install_github("Azure/rAzureBatch")
# Install the doAzureParallel package
devtools::install_github("Azure/doAzureParallel") # Load the doAzureParallel library
library(doAzureParallel) Next, you need to create an Azure Batch and a storage account in your Azure subscription. Jot down the access keys and save them in a json file with the following structure:
{
"batchAccount": {
"name": "your-batchaccount-name-here",
"key": "your-key-here",
"url": "your-url-here"
},
"storageAccount": {
"name": "your-storageaccount-name-here",
"key": "your-key-here"
},
"githubAuthenticationToken": ""
}Leave the github part blank. Now we need to load the credentials into our current R session:
setCredentials(paste0(path_credentials, "azure-batch-credentials.json"))Then you need to specify the compute ressources Azure Batch is allowed to use. You can generate a configuration JSON in your current working directory using:
generateClusterConfig("cluster.json")Per default, your batch includes 3 dedicated nodes and 3 low-priority nodes. Low-priority nodes are significantely cheaper, but may become unavailable if Azure needs additional capacity for other customers using normal nodes. I changed the configuration to include only low-priority nodes:
{
"name": "myTestPool",
"vmSize": "Standard_D2_v2",
"maxTasksPerNode": 2,
"poolSize": {
"dedicatedNodes": {
"min": 0,
"max": 0
},
"lowPriorityNodes": {
"min": 3,
"max": 3
},
"autoscaleFormula": "QUEUE"
},
"containerImage": "rocker/tidyverse:latest",
"rPackages": {
"cran": ["xgboost", "caret"],
"github": [],
"bioconductor": []
},
"commandLine": []
}As you can see, Azure Batch uses a Docker image based on rocker/tidyverse and you can also specify additional packages to install. You can use different Docker images from Dockerhub or your own.
The following graphic from RevolutionAnalytics.com gives a nice overview about how that works:
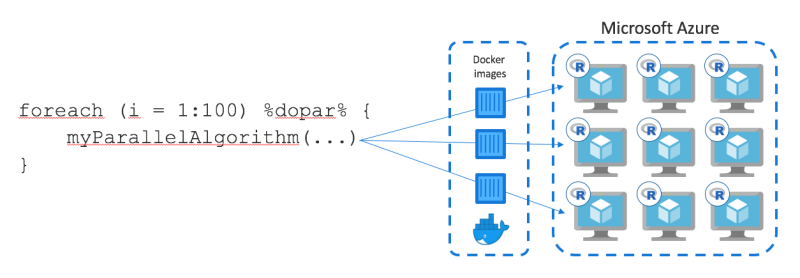
doAzureParallel
The VMs we request have 2 cores each and 7GB of RAM and cost about € 0.12/hour as normal nodes and only € 0.02/hour in low-priority mode. Microsoft offers the following rule of thumb in choosing an appropriate VM:
- Av2 Series: economical, general purpose
- F Series: compute intensive workloads
- Dv2 Series: memory intensive workloads
Now we can create our cluster (might take a few minutes) and register it as a foreach backend:
cluster = makeCluster("cluster.json")
## Re-establish connection to cluster (e.g. after R crashes):
# cluster = getCluster("myTestPool")
registerDoAzureParallel(cluster)
workers = getDoParWorkers() The number of ‘execution workers’ = # nodes x maxTasksPerNode. When you look at message generated by generateClusterConfig() there is a note saying that to maximize all CPU corese, you shoult set maxTasksPerNote to 4x the number of cores of the VM you specified.
Let’s try our cluster by training a XGBoost model in a parallel fashion:
Install packages
As you can already see from the cluster.json file you can specifiy to install packages from:
- CRAN:
["cran_package_name_1", "cran_package_name_2"] - Github:
["github_username/github_package_1", "another_github_username/another_github_package_2"] - Bioconductor:
["some_bioconductor_package"]
You can also install packages from private github repos if you provide a Github authentification token in your credentials.json file.
You can also provide a custom docker image that already comes with all necessary packages.
It is also possible to install packages individually per foreach-loop like so:
results = foreach(i = 1:number_of_iterations,
.packages= c('package_1', 'package_2'),
github = c('github_username/github_package_1', 'github_username/github_package_2'),
bioconductor = c('package_1', 'package_2')
) %dopar% { ... }Currently, you cannot uninstall packages from a pool. Simply stop the cluster and start a new one.
Data movement
Export local R session (default)
Since doAzureParallel is simply a foreach backend by default it exports the data you have in your local R session to all nodes. However, this implies that your data must fit into local memory and into memory of your workers.
data = some_input_data
results = foreach(i = 1:10) %dopar% {
some_algorithm(data)
}Export data using iterators
Another alternative is to use iterators from the iterators package to split the data into parts and only distribute the relevant parts to each worker:
## a dataset with a column called 'col_group' that we can use to split the data
## into parts that allow parallel processing
data = some_data_set
## generate (roughly) equal group sizes for workers
workers_splits = as.factor(as.numeric(as.factor(data[[col_group]]))%%workers)
## generate iterator and split data into groups for workers to process
iter_data = iterators::isplit(x = data, f = workers_splits) %dopar% {...}Pre-load data into cluster
You can pre-load data into your cluster when it is created using resource files. You can find more information on setting up resource files here
When you are done, it is important to stop the cluster. Otherwise, you will continue to incur charges.
stopCluster(cluster)Saving money
Using low-priority VMs is an obvious way to save a significant chunk of money, but you can also use the ‘Autoscale’ feature to automatically change your cluster depending on your needs. doAzureParallel offers 4 autoscaling options out-of-the-box:
- QUEUE: scale pool based on amount of work in queue
- WORKDAY: use MAX from Monday - Friday during business hours (8.00 - 18.00), else MIN
- WEEKEND: use MAX on Saturday and Sunday, else MIN
- MAX_CPU: Minimum average CPU usage > 70% increases pool by 1.1X
To use auto-scaling, you need to set minimum < maximum number of nodes for both low prio and dedicated VMs.
Limits
Azure Batch can use up to 20 cores by default (irrespective of VM type), but you can request a higher limit by contacting Microsoft customer support.
You cannot run more than 20 foreach loops at a time, because each loop corresponds to 1 job and users are limited to 20 jobs in total.